Precision in data collection and analysis is crucial for researchers seeking reliable outcomes. One powerful methodology that enhances precision in experimental settings is the Randomized Block Design (RBD). This approach allows for minimizing variability and improving the accuracy of statistical tests, leading to more reliable conclusions.
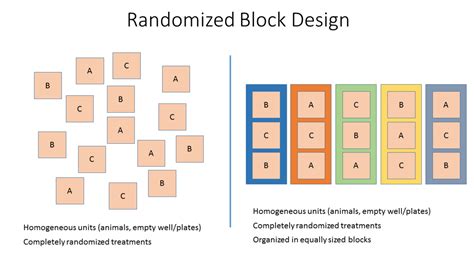
A randomized block design organizes experimental units into homogeneous groups known as blocks. Each block contains homogeneous units that are similar in terms of specific extraneous variables. The treatment is then randomly applied within each block, ensuring that variations due to blocking factors are accounted for, thus improving the precision of the estimates of treatment effects.
To master RBD, consider these critical insights:
Key Insights
- The primary insight with practical relevance is that using RBD enhances the precision of statistical inferences by controlling for extraneous variability.
- A technical consideration involves ensuring that the blocks are appropriately defined to match the relevant variability present in your experimental units.
- An actionable recommendation is to conduct a preliminary study to identify and categorize potential extraneous variables that could influence your results.
Understanding Randomized Block Design: Structure and Benefits
The fundamental structure of a randomized block design involves dividing the experimental material into blocks and applying treatments randomly within each block. This methodology is especially useful when dealing with field experiments where conditions like soil type or sunlight exposure can vary across different locations. By blocking the experimental units, researchers can ensure that these extraneous factors do not confound their results.
For instance, consider an agricultural study evaluating the effects of different fertilizers on crop yield. Without proper blocking, variability due to soil quality could mask the true effect of the fertilizers. By grouping plots of similar soil quality into blocks and then randomly assigning fertilizers within each block, researchers can isolate the treatment effect, yielding more precise and reliable data.
Advantages and Practical Application of Randomized Block Design
The benefits of randomized block design extend beyond controlling for extraneous variables. Firstly, it increases the statistical power of an experiment by reducing within-group variability, which means that smaller sample sizes may suffice to detect treatment effects. This is especially beneficial in scenarios where large-scale experiments are impractical.
In practical terms, suppose we are conducting a medical trial to compare the effectiveness of two drugs. If patients exhibit significant variability in age, weight, and overall health, these factors could skew results. By grouping patients into blocks based on these characteristics and randomly assigning drugs within each block, researchers can more accurately determine which drug is more effective.
FAQ Section
How many blocks should be used in an RBD?
The number of blocks depends on the level of variability and the number of treatments. Ideally, blocks should be large enough to minimize within-block variability but not so large that they lose the ability to differentiate treatments effectively.
Can RBD be applied in all types of research?
While RBD is highly versatile, its application depends on the research context. It is most effective in scenarios where extraneous variability is a concern, such as agricultural and clinical studies.
Mastering the randomized block design involves understanding and applying this powerful methodological tool to control extraneous variability and improve the precision of your data. By incorporating practical steps and insights, researchers can enhance the reliability of their findings and draw more confident conclusions from their experiments.