Understanding right-skewed distributions is crucial for any data analyst or business professional who relies on data-driven decision-making. When data points are more concentrated on the lower end of the scale with a long tail stretching towards higher values, it indicates a right-skewed distribution. This guide will help you decode this concept with actionable advice, practical solutions, and real-world examples to make your analysis more effective. Let’s dive into the essentials of understanding and leveraging right-skewed distributions to enhance your data analysis.
Why Understanding Right Skewed Distribution Matters
Right-skewed distributions occur in many real-world scenarios. Whether it’s income distribution, sales figures, or even test scores, the skew can provide significant insights into the underlying patterns and behaviors in the data. Knowing how to identify and interpret these distributions can help you make better predictions, avoid biases, and improve your overall data-driven strategies.
Common Challenges and How to Address Them
Many people struggle with identifying skewness in their data and understanding its implications. Here are some common pain points:
- Difficulty in recognizing skewness without statistical knowledge.
- Challenges in interpreting skewness and its impact on analysis.
- Concerns about over-correcting skewed data which might distort the natural distribution.
Quick Reference
Quick Reference
- Immediate action item: Always start by plotting your data using a histogram to visually identify skewness.
- Essential tip: Use the skewness coefficient to quantitatively measure the skew. A value greater than 0 indicates right skew.
- Common mistake to avoid: Don’t try to normalize skewed data without considering the underlying distribution; it can lead to distorted analyses.
Identifying Right Skewed Distributions
To start with identifying right-skewed distributions, you need to understand the visual and statistical indicators.
Visual Indicators
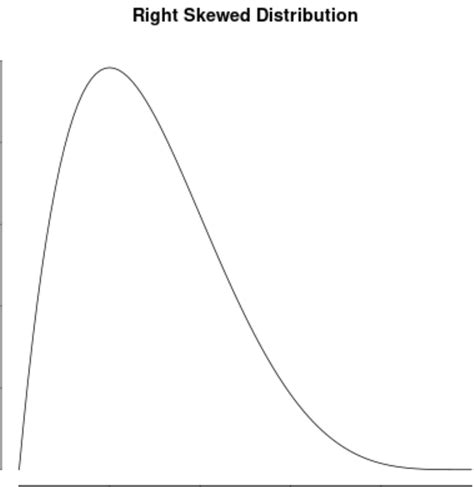
A visual inspection of the histogram or a box plot can provide immediate clues about skewness. Right-skewed distributions typically show:
- Mean greater than the median.
- Longer tail extending towards higher values.
For instance, if you are analyzing household incomes, you’ll often find that the mean income is higher than the median, with most households earning less than the average.
Statistical Indicators
To quantitatively confirm skewness, use statistical measures:
1. Skewness Coefficient: This measures how asymmetric the distribution is about its mean. Positive values indicate right skew, while negative values indicate left skew. A common method is Karl Pearson’s coefficient of skewness:
Formula: Skewness = (Mean - Median) / Standard Deviation
2. Skewness Index: This is another measure that helps you understand the degree of skew. It ranges from -3 to +3. Values closer to +1 indicate higher skewness.
Practical Example
Consider a dataset of sales figures for a retail store. If you plot the data, you notice a longer tail extending towards higher sales figures. By calculating the skewness coefficient, you find a value greater than 0, confirming right skewness. This suggests that while a few stores achieve high sales, most sell below the average.
Interpreting Right Skewed Distributions
Understanding the implications of right skew in your data is essential for accurate analysis and decision-making.
Real-world Applications
Right-skewed distributions appear frequently in real-world contexts:
- Income Distribution: Most people earn less than the average income.
- Test Scores: A few students score exceptionally high, skewing the overall distribution.
- Sales Data: A small number of transactions account for a large percentage of total revenue.
Analyzing these distributions helps in understanding underlying factors, such as economic disparities, educational performance, and sales strategies.
Decision-making Implications
When faced with right-skewed data:
- Rely on median instead of mean for a more accurate central tendency.
- Use log transformations or other methods to normalize data if performing statistical tests.
- Consider the impact of outliers on your analysis and decision-making.
How to Handle Right Skewed Distributions
Handling right-skewed distributions requires a strategic approach to maintain the integrity and usability of your data.
Basic Techniques
Start with these foundational techniques to manage skewness:
- Use robust statistical measures: Median, interquartile range (IQR) instead of mean and standard deviation.
- Apply transformations: Logarithmic, square root, or other functions to bring the distribution closer to normal.
For example, if analyzing income data, you can use the median to report central tendency and log-transform the data before applying certain statistical tests.
Advanced Techniques
For more sophisticated applications, consider these advanced strategies:
- Applying non-parametric tests: These don’t assume a normal distribution and can handle skewness effectively.
- Using regression analysis: Skewed data can sometimes be better modeled using techniques like generalized linear models which account for non-normality.
- Advanced transformations: Box-Cox transformations can be particularly useful in bringing highly skewed data to a more manageable form.
Practical Example
Imagine you’re working on a project analyzing customer acquisition costs for a marketing campaign. The data is right-skewed, with a few very high costs skewing the average. Here’s how to handle it:
1. Calculate the median cost and report it for a better central tendency measure.
2. Log-transform the data: log(acquisition_cost + 1) to reduce the skewness and stabilize variance. Add 1 to avoid log of zero.
3. Run your statistical tests or regression models on the transformed data.
4. Reverse the transformation for reporting and interpretation.
FAQ Section
What are common mistakes to avoid when dealing with right-skewed distributions?
Here are several common mistakes and how to avoid them:
- Ignoring skewness: Always check for skewness when analyzing data. Ignoring it can lead to incorrect conclusions.
- Misusing statistical measures: Don’t rely solely on mean and standard deviation; use median and IQR for a better understanding of the central tendency and spread.
- Over-correcting data: Applying heavy transformations can distort data. Assess the need carefully and choose the least invasive method that addresses skewness.
- Not considering outliers: Be aware of the impact of outliers on your analysis. They can disproportionately influence the results.
Best Practices for Working with Right Skewed Distributions
To ensure effective data analysis, follow these best practices:
- Always plot your data: Use histograms or box plots to visually inspect for skewness.
- Quantify skewness: Use skewness coefficient and index to quantitatively measure the skew.
- Choose appropriate measures: Use median, IQR, and other robust measures instead of mean and standard deviation.
- Transformations when needed: Apply transformations sparingly and only when necessary to normalize the data for certain analyses.
- Consider advanced techniques: Use non-parametric tests, regression models, and advanced transformations if required.
By following these guidelines, you can effectively identify, interpret, and handle right-skewed distributions, enhancing the quality and reliability of your data analysis.